What Are Transformers in AI#
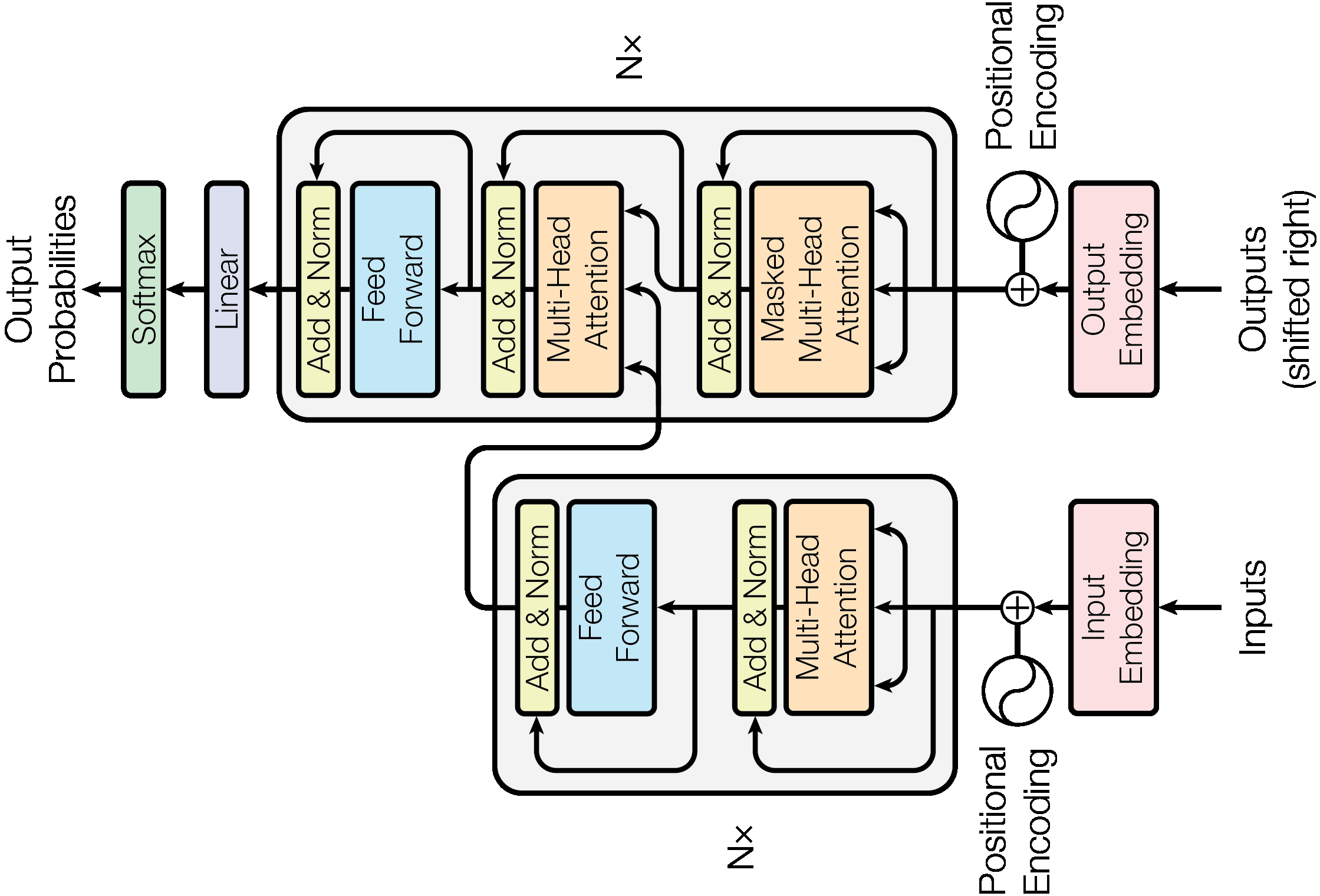
Transformer Architecture#
Background#
Whether GPT, ChatGPT, DALL-E, Whisper, Satablity AI or whatever significant you see in the AI worlds nowdays it is because of Transformer Architecture. Transformers are a type of neural network architecture that have several properties that make them effective for modeling data with long-range dependencies. They generally feature a combination of multi-headed attention mechanisms, residual connections, layer normalization, feedforward connections, and positional embeddings.
Precursors of Transformers were RNN, LSTM, and GRU architecture. Transformers are based on the 2017 research paper “Attention is All You Need”
Initially, Transformers were used for NLP-related tasks. Slowly researchers started exploring the power of the Transformer Architectures and as of 2023 these are used for hundreds of tasks in different AI domains of technologies like:
- Text Models (NLP, NLU, NLG)
- Vision Models (Computer Vision)
- Audio Models (Audio Processing, Classification, Audio Generation)
- Reinforcement (RL) Models
- Time-series Models
- Multimodal: OCR (extract information from scanned documents), video classification, visual QA, table data question answering
- Graph Models
Starting the journey in 2017, as of now (2023) we have approx 200 Transformer based architectures proposed by various researchers for various purposes. Using these architecture and various benchmark datasets thousands of models have been created which give SOTA performance on various tasks. Based on your need you choose which architecture can help you meet your project objective. There are high chances you will get some pre-trained models which you can use without training (Zero-shot) or small finetuning (one-shot or few-shot) efforts. For that you need to explore Huggingface and PaperWithCode
This articles list all the major Transformer related researcher paper, their creators, capability and date of release.
Tasks, which a Transformer can do#
Vision Tasks#
- Image classification
- Semantic segmentation
- Video classification
- Object detection
- Zero-shot object detection
- Zero-shot image classification
- Depth estimation
Multimodal Tasks#
- Image captioning
- Document Question Answering
- Image to Text
- Text to Video
- Document Question Answering
- Visual Question Answering
- Text to Image
- Image to Image
- Image Generation
Audio Tasks#
- Audio classification
- Automatic speech recognition
- Audio to Audio
- Text to Speech
- Voice Activity Detection
- Audio Generation
Text Tasks#
- Text classification
- Token classification (NER, POS etc)
- Question answering
- Causal language modeling
- Masked language modeling
- Translation
- Summarization
- Multiple choice
- Sentence Similarity
- Table Question Answering
- Fill in the black (Masking Filling)
- Conversation
Frameworks Used for Developing Models using Above Architectures#
As of May'2023 following frameworks are used for creating models. Tensorflow and Pytorch are two most popular frameworks. Keras is not part of Tensorflow.
- TensorFlow
- Caffe
- Caffe2
- PyTorch
- MXNet
- Keras
- Chainer
- JAX
Number of Models in Model Repositories#
There are many model repositories but the most famous are as below. These model repositories host pre-trained models. You can download these models and use them for your project.
- Huggingface : As of 2-Jul-23 Huggingface has 243,495 models. In May, 2023, Huggingface has 196,000+ models in the repository. As of Sep'2021, there were 10,000 models. You can see the exponential growth in the models in the Huggingface model repository.
- Another model repository tfhub has around 132,000+ models as of May'23. Tfhub hosts tensorflow-based models.
- Keras Moel Zoo hosts around 3500 models.
- Pytorch Model Hub
Summary of 200+ Transformer#
Below is the table which summarises these approx 200 transformers.
Note : Name starting with * are not Transformers, most of them are pretransformer age architectures.
Help Needed: If you find any archive paper’s link is incorrect then let me know via hari.prasad@vedavit-ps.com
| Sno. | Transformer | Paper Title | Type | Year | Researcher |
|---|---|---|---|---|---|
| 1. | *AlexNet Paper | ImageNet Classification with Deep Convolutional Neural Networks | CNN | Dec-2012 | University of Toronto, Google |
| 2. | *VGG16 Paper | Very Deep Convolutional Networks for Large-Scale Image Recognition | CNN | Sep-2014 | University of Oxford |
| 3. | *VGG19 Paper | Very Deep Convolutional Networks for Large-Scale Image Recognition | CNN | Apr-2015 | University of Oxford |
| 4. | *ResNet Paper | Deep Residual Learning for Image Recognition | CNN | Dec-2015 | Microsoft Research |
| 5. | *InceptionResNet Paper | Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning | CNN | Aug-2016 | |
| 6. | *ConvNeXt Paper | Convolutional Neural Networks with Alternately Updated Clique | CNN | Dec-2016 | Cornell University, Tsinghua University |
| 7. | *DenseNet Paper | Densely Connected Convolutional Networks | CNN | Jan-2017 | Cornell University, Tsinghua University |
| 8. | *MobileNetV1 Paper | Efficient Convolutional Neural Networks for Mobile Vision Applications | Autoencoding | Apr-2017 | Google Inc. |
| 9. | *Xception Paper | Xception: Deep Learning with Depthwise Separable Convolutions | CNN | Apr-2017 | |
| 10. | EncoderDecoder Paper | Leveraging Pre-trained Checkpoints for Sequence Generation Tasks | Sequence-to-Sequence | May-2017 | Google Research |
| 11. | *MobileNetV2 Paper | Inverted Residuals and Linear Bottlenecks | Autoencoding | Feb-2018 | Google Inc. |
| 12. | Data2Vec Paper | A General Framework for Self-supervised Learning in Speech, Vision and Language | Language Model | Mar-2018 | |
| 13. | GPT Paper | Improving Language Understanding by Generative Pre-Training. Auto-regressive model for next token prediction | Autoregressive | Jun-2018 | OpenAI |
| 14. | BERT Paper | Pre-training of Deep Bidirectional Transformers for Language Understanding | Autoencoding | Oct-2018 | |
| 15. | MarianMT Paper | Machine translation models trained using OPUS data | Autoencoding | Oct-2018 | |
| 16. | BiT Paper | General Visual Representation Learning | Vision Transformer | Jan-2019 | Google AI |
| 17. | Transformer-XL Paper | Attentive Language Models Beyond a Fixed-Length Context | Autoregressive | Jan-2019 | Google/CMU |
| 18. | XLM Paper | Cross-lingual Language Model Pretraining | BERT-based | Jan-2019 | |
| 19. | CTRL Paper | A Conditional Transformer Language Model for Controllable Generation | Autoencoding | Feb-2019 | Salesforce |
| 20. | GPT-2 Paper | Language Models are Unsupervised Multitask Learners | Autoregressive | Feb-2019 | OpenAI |
| 21. | Funnel Transformer Paper | Filtering out Sequential Redundancy for Efficient Language Processing | Autoregressive | Apr-2019 | CMU/Google Brain |
| 22. | *EfficientNet B0 Paper | EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks | CNN | May-2019 | Google Research |
| 23. | ALBERT Paper | A Lite BERT for Self-supervised Learning of Language Representations, | Factorized BERT | May-2019 | Google Research and the Toyota Technological Institute at Chicago |
| 24. | EfficientNet Paper | Rethinking Model Scaling for Convolutional Neural Networks | Vision Transformer | May-2019 | Google Brain |
| 25. | MobileNetV3 Paper | Searching for MobileNetV3 | Autoencoding | May-2019 | |
| 26. | Nezha Paper | Neural Contextualized Representation for Chinese Language Understanding | Autoencoding | May-2019 | Huawei Noah’s Ark Lab |
| 27. | BART Paper | Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension | Sequence-to-Sequence | Jun-2019 | |
| 28. | ERNIE Paper | Enhanced Representation through Knowledge Integration | Autoencoding | Jun-2019 | Baidu |
| 29. | ErnieM Paper | Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora | Autoencoding | Jun-2019 | Baidu |
| 30. | FlauBERT Paper | Unsupervised Language Model Pre-training for French | Autoencoding | Jun-2019 | CNRS |
| 31. | LXMERT Paper | Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering | Autoencoding | Jun-2019 | UNC Chapel Hill |
| 32. | Pegasus Paper | Pre-training with Extracted Gap-sentences for Abstractive Summarization | Autoregressive | Jun-2019 | |
| 33. | XLNet Paper | Generalized Autoregressive Pretraining for Language Understanding | Autoregressive | Jun-2019 | Google/CMU |
| 34. | BioGpt Paper | generative pre-trained transformer for biomedical text generation and mining | Autoregressive | Jul-2019 | Microsoft Research AI4Science |
| 35. | Hubert Paper | Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units | Autoencoding | Jul-2019 | |
| 36. | REALM Paper | Retrieval-Augmented Language Model Pre-Training | Hybrid | Jul-2019 | Google Research |
| 37. | SpeechToTextTransformer Paper | Fast Speech-to-Text Modeling with fairseq | Hybrid | Jul-2019 | Facebook, |
| 38. | XLM-V Paper | Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models | Multilingual | Jul-2019 | Meta AI |
| 39. | RoBERTa Paper | A Robustly Optimized BERT Pretraining Approach | BERT-based | Aug-2019 | |
| 40. | GPT Neo Paper | EleutherAI/gpt-neo | Autoregressive | Sep-2019 | EleutherAI |
| 41. | CamemBERT Paper | a Tasty French Language Model | Autoencoding | Oct-2019 | Inria/Facebook/Sorbonne |
| 42. | DialoGPT Paper | Large-Scale Generative Pre-training for Conversational Response Generation | Autoregressive | Oct-2019 | Microsoft Research |
| 43. | DistilBERT Paper | smaller, faster, cheaper and lighter | Autoencoding | Oct-2019 | HuggingFace |
| 44. | LiLT Paper | A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding | Autoencoding | Oct-2019 | South China University of Technology |
| 45. | LUKE Paper | Deep Contextualized Entity Representations with Entity-aware Self-attention | Autoencoding | Oct-2019 | Studio Ousia |
| 46. | MobileBERT Paper | a Compact Task-Agnostic BERT for Resource-Limited Devices | Autoencoding | Oct-2019 | CMU/Google Brain |
| 47. | MT5 Paper | A massively multilingual pre-trained text-to-text transformer | Autoregressive | Oct-2019 | Google AI |
| 48. | RAG Paper | Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks | Hybrid | Oct-2019 | |
| 49. | ConvBERT Paper | Improving BERT with Span-based Dynamic Convolution | Autoencoding | Nov-2019 | YituTech |
| 50. | Megatron-GPT2 Paper | Training Multi-Billion Parameter Language Models Using Model Parallelism | Autoregressive | Nov-2019 | NVIDIA |
| 51. | PhoBERT Paper | Pre-trained language models for Vietnamese | BERT-based | Nov-2019 | VinAI Research |
| 52. | RoBERTa-PreLayerNorm Paper | A Fast, Extensible Toolkit for Sequence Modeling | BERT-based | Nov-2019 | |
| 53. | BERTweet Paper | A pre-trained language model for English Tweets | Autoencoding | Dec-2019 | VinAI Research |
| 54. | mBART Paper | Multilingual Denoising Pre-training for Neural Machine Translation | Autoregressive | Dec-2019 | |
| 55. | Megatron-BERT Paper | Training Multi-Billion Parameter Language Models Using Model Parallelism | Autoregressive | Dec-2019 | NVIDIA |
| 56. | SpeechToTextTransformer2 Paper | Large-Scale Self- and Semi-Supervised Learning for Speech Translation | Hybrid | Dec-2019 | Facebook, |
| 57. | BERT For Sequence Generation Paper | Leveraging Pre-trained Checkpoints for Sequence Generation Tasks | Autoencoding | Feb-2020 | |
| 58. | ConvNeXT Paper | A ConvNet for the 2020s | Vision Transformer | Mar-2020 | Facebook AI |
| 59. | ELECTRA Paper | Pre-training text encoders as discriminators rather than generators | Autoencoding | Apr-2020 | Google Research/Stanford University |
| 60. | Longformer Paper | The Long-Document Transformer | Autoregressive | Apr-2020 | AllenAI |
| 61. | RegNet Paper | Designing Network Design Space | CNN | Apr-2020 | META Platforms |
| 62. | SqueezeBERT Paper | What can computer vision teach NLP about efficient neural networks? | BERT-based | Apr-2020 | Berkeley |
| 63. | LayoutLM Paper | Pre-training of Text and Layout for Document Image Understanding | Autoencoding | May-2020 | Microsoft Research Asia |
| 64. | MPNet Paper | Masked and Permuted Pre-training for Language Understanding | Autoencoding | May-2020 | Microsoft Research |
| 65. | VisualBERT Paper | A Simple and Performant Baseline for Vision and Language | BERT-based | May-2020 | UCLA NLP |
| 66. | Conditional DETR Paper | Conditional DETR for Fast Training Convergence | Vision Transformer | Jun-2020 | Microsoft Research Asia |
| 67. | GPTBigCode Paper | don’t reach for the stars! | Autoregressive | Jun-2020 | BigCode |
| 68. | M-CTC-T Paper | Pseudo-Labeling For Massively Multilingual Speech Recognition | Autoencoding | Jun-2020 | |
| 69. | Pix2Struct Paper | Screenshot Parsing as Pretraining for Visual Language Understanding | Hybrid | Jun-2020 | |
| 70. | ProphetNet Paper | Predicting Future N-gram for Sequence-to-Sequence Pre-training | Autoregressive | Jun-2020 | Microsoft Research |
| 71. | SEW Paper | Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition | Vision Transformer (ViT) | Jun-2020 | ASAPP |
| 72. | T5 Paper | Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer | Autoregressive | Jun-2020 | Google AI |
| 73. | DeBERTa Paper | Decoding-enhanced BERT with Disentangled Attention | Autoencoding | Jul-2020 | Microsoft |
| 74. | Informer Paper | Beyond Efficient Transformer for Long Sequence Time-Series Forecasting | Autoencoding | Jul-2020 | Beihang University, UC Berkeley, Rutgers University, SEDD Company |
| 75. | LED Paper | The Long-Document Transformer | Autoregressive | Jul-2020 | AllenAI |
| 76. | SwitchTransformers Paper | Scaling to Trillion Parameter Models with Simple and Efficient Sparsity | Hybrid | Jul-2020 | |
| 77. | Whisper Paper | Robust Speech Recognition via Large-Scale Weak Supervision | Autoregressive | Jul-2020 | OpenAI |
| 78. | XLM-ProphetNet Paper | Predicting Future N-gram for Sequence-to-Sequence Pre-training | Hybrid | Jul-2020 | Microsoft Research |
| 79. | XLM-RoBERTa Paper | Unsupervised Cross-lingual Representation Learning at Scale | BERT-based | Jul-2020 | Facebook AI, |
| 80. | Deformable DETR Paper | Deformable Transformers for End-to-End Object Detection | Vision Transformer | Aug-2020 | SenseTime Research |
| 81. | FNet Paper | Mixing Tokens with Fourier Transforms | Autoencoding | Aug-2020 | Google Research |
| 82. | GPTSAN-japanese Paper | released in the repository tanreinama/GPTSAN | Autoregressive | Aug-2020 | |
| 83. | SEW-D Paper | Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition | Vision Transformer (ViT) | Aug-2020 | ASAPP |
| 84. | CPM Paper | A Large-scale Generative Chinese Pre-trained Language Model | Sequence-to-Sequence | Sep-2020 | Tsinghua University |
| 85. | GIT Paper | A Generative Image-to-text Transformer for Vision and Language | Autoencoding | Sep-2020 | Microsoft Research |
| 86. | LayoutXLM Paper | Multimodal Pre-training for Multilingual Visually-rich Document Understanding | Autoencoding | Sep-2020 | Microsoft Research Asia |
| 87. | DETR Paper | End-to-End Object Detection with Transformers | Vision Transformer | Oct-2020 | |
| 88. | GPT NeoX Paper | An Open-Source Autoregressive Language Model | Autoregressive | Oct-2020 | EleutherAI |
| 89. | RemBERT Paper | Rethinking embedding coupling in pre-trained language models | BERT-based | Oct-2020 | Google Research |
| 90. | RoCBert Paper | Robust Chinese Bert with Multimodal Contrastive Pretraining | BERT-based | Oct-2020 | WeChatAI |
| 91. | TAPAS Paper | Weakly Supervised Table Parsing via Pre-training | Hybrid | Oct-2020 | Google AI |
| 92. | UPerNet Paper | Unified Perceptual Parsing for Scene Understanding | Vision Transformer (ViT) | Oct-2020 | Peking University |
| 93. | Vision Transformer (ViT) Paper | Transformers for Image Recognition at Scale | Vision Transformer (ViT) | Oct-2020 | Google AI |
| 94. | Wav2Vec2 Paper | A Framework for Self-Supervised Learning of Speech Representations | Autoregressive | Oct-2020 | Facebook AI |
| 95. | PLBart Paper | Unified Pre-training for Program Understanding and Generation | Hybrid | Nov-2020 | UCLA NLP |
| 96. | DiT Paper | Self-supervised Pre-training for Document Image Transformer | Vision Transformer | Dec-2020 | Microsoft Research |
| 97. | DPR Paper | Dense Passage Retrieval for Open-Domain Question Answering | Sequence-to-Sequence | Dec-2020 | |
| 98. | GLPN Paper | Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth | Autoencoding | Dec-2020 | KAIST |
| 99. | LeViT Paper | A Vision Transformer in ConvNet’s Clothing for Faster Inference | Autoencoding | Dec-2020 | Meta AI |
| 100. | NAT Paper | Neighborhood Attention Transformer | Autoencoding | Dec-2020 | SHI Labs |
| 101. | TAPEX Paper | Table Pre-training via Learning a Neural SQL Executor | Hybrid | Dec-2020 | Microsoft Research |
| 102. | VideoMAE Paper | Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training | Hybrid | Dec-2020 | Multimedia Computing Group, Nanjing University |
| 103. | Wav2Vec2-Conformer Paper | Fast Speech-to-Text Modeling with FAIRSEQ | Autoregressive | Dec-2020 | Facebook AI |
| 104. | CLIP Paper | Learning Transferable Visual Models From Natural Language Supervision | Vision-Language Pretraining | Jan-2021 | OpenAI |
| 105. | XLS-R Paper | Self-supervised Cross-lingual Speech Representation Learning at Scale | Autoregressive | Jan-2021 | Facebook AI |
| 106. | Audio Spectrogram Transformer Paper | Audio Spectrogram Transformer | Audio Transformer | Feb-2021 | MIT |
| 107. | M2M100 Paper | Beyond English-Centric Multilingual Machine Translation | Autoregressive | Feb-2021 | |
| 108. | MEGA Paper | Moving Average Equipped Gated Attention | Autoencoding | Feb-2021 | |
| 109. | BEiT Paper | BERT Pre-Training of Image Transformers | Vision Transformer | Mar-2021 | Microsoft |
| 110. | BigBird-Pegasus Paper | Transformers for Longer Sequences | Sequence-to-Sequence | Mar-2021 | Google Research |
| 111. | BigBird-RoBERTa Paper | Transformers for Longer Sequences | Autoencoding | Mar-2021 | Google Research |
| 112. | CLIPSeg Paper | Image Segmentation Using Text and Image Prompts | Vision-Language Pretraining | Mar-2021 | University of Göttingen |
| 113. | DPT Paper | Vision Transformers for Dense Prediction | Vision Transformer | Mar-2021 | Intel Labs |
| 114. | Perceiver IO Paper | A General Architecture for Structured Inputs & Outputs | Hybrid | Mar-2021 | Deepmind |
| 115. | Reformer Paper | The Efficient Transformer | Hybrid | Mar-2021 | Google Research |
| 116. | RoFormer Paper | Enhanced Transformer with Rotary Position Embedding | Hybrid | Mar-2021 | ZhuiyiTechnology |
| 117. | Swin Transformer Paper | Hierarchical Vision Transformer using Shifted Windows | Vision Transformer (ViT) | Mar-2021 | Microsoft |
| 118. | TrOCR Paper | Transformer-based Optical Character Recognition with Pre-trained Models | Hybrid | Mar-2021 | Microsoft, |
| 119. | Wav2Vec2Phoneme Paper | Simple and Effective Zero-shot Cross-lingual Phoneme Recognition | Autoregressive | Mar-2021 | Facebook AI |
| 120. | X-CLIP Paper | Expanding Language-Image Pretrained Models for General Video Recognition | Hybrid | Mar-2021 | Microsoft Research |
| 121. | XLSR-Wav2Vec2 Paper | Unsupervised Cross-Lingual Representation Learning For Speech Recognition | Autoregressive | Mar-2021 | Facebook AI |
| 122. | Blenderbot Paper | Recipes for building an open-domain chatbot | Sequence-to-Sequence | Apr-2021 | |
| 123. | BlenderbotSmall Paper | Recipes for building an open-domain chatbot | Sequence-to-Sequence | Apr-2021 | |
| 124. | BLIP Paper | Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation | Vision Transformer | Apr-2021 | Salesforce |
| 125. | ByT5 Paper | Towards a token-free future with pre-trained byte-to-byte models | Sequence-to-Sequence | Apr-2021 | Google Research |
| 126. | CvT Paper | Introducing Convolutions to Vision Transformers | Vision Transformer | Apr-2021 | Microsoft |
| 127. | DeBERTa-v2 Paper | Decoding-enhanced BERT with Disentangled Attention | Autoencoding | Apr-2021 | Microsoft |
| 128. | DeiT Paper | Training data-efficient image transformers & distillation through attention | Vision Transformer | Apr-2021 | |
| 129. | GroupViT Paper | Semantic Segmentation Emerges from Text Supervision | Autoencoding | Apr-2021 | UCSD, NVIDIA |
| 130. | LayoutLMv2 Paper | Multi-modal Pre-training for Visually-Rich Document Understanding | Autoencoding | Apr-2021 | Microsoft Research Asia |
| 131. | MaskFormer Paper | Per-Pixel Classification is Not All You Need for Semantic Segmentation | Autoencoding | Apr-2021 | Meta and UIUC |
| 132. | SegFormer Paper | Simple and Efficient Design for Semantic Segmentation with Transformers | Hybrid | Apr-2021 | NVIDIA |
| 133. | Time Series Transformer Paper | Hybrid | Apr-2021 | HuggingFace. | |
| 134. | TimeSformer Paper | Space-Time Attention All You Need for Video Understanding? | Hybrid | Apr-2021 | |
| 135. | Trajectory Transformer Paper | Offline Reinforcement Learning as One Big Sequence Modeling Problem | Hybrid | Apr-2021 | the University of California at Berkeley |
| 136. | UniSpeech Paper | Unified Speech Representation Learning with Labeled and Unlabeled Data | Hybrid | Apr-2021 | Microsoft Research |
| 137. | UniSpeechSat Paper | UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING | Hybrid | Apr-2021 | Microsoft Research |
| 138. | ALIGN Paper | Scaling Up Visual and Vision-Language. Representation Learning With Noisy Text Supervision | Vision Transformer | May-2021 | Google Research |
| 139. | BORT Paper | Optimal Subarchitecture Extraction For BERT | Sequence-to-Sequence | May-2021 | Alexa |
| 140. | DePlot Paper | One-shot visual language reasoning by plot-to-table translation | Vision Transformer | May-2021 | Google AI |
| 141. | DETA Paper | NMS Strikes Back | Sequence-to-Sequence | May-2021 | The University of Texas at Austin |
| 142. | DiNAT Paper | Dilated Neighborhood Attention Transformer | Vision Transformer | May-2021 | SHI Labs |
| 143. | Jukebox Paper | A Generative Model for Music | Autoencoding | May-2021 | OpenAI |
| 144. | mBART-50 Paper | Multilingual Translation with Extensible Multilingual Pretraining and Finetuning | Autoregressive | May-2021 | |
| 145. | Nyströmformer Paper | A Nyström-Based Algorithm for Approximating Self-Attention | Autoencoding | May-2021 | the University of Wisconsin - Madison |
| 146. | ViT Hybrid Paper | Transformers for Image Recognition at Scale | Hybrid | May-2021 | Google AI |
| 147. | X-MOD Paper | Lifting the Curse of Multilinguality by Pre-training Modular Transformers | Hybrid | May-2021 | Meta AI |
| 148. | BARTpho Paper | Pre-trained Sequence-to-Sequence Models for Vietnamese | Autoregressive | Jun-2021 | VinAI Research |
| 149. | BridgeTower Paper | Building Bridges Between Encoders in Vision-Language Representation Learning | Vision Transformer | Jun-2021 | Harbin Institute of Technology/Microsoft Research Asia/Intel Labs |
| 150. | CodeGen Paper | A Conversational Paradigm for Program Synthesis | Vision Transformer | Jun-2021 | Salesforce |
| 151. | GPT-J Paper | released in the repository kingoflolz/mesh-transformer-jax | Autoregressive | Jun-2021 | EleutherAI |
| 152. | LLaMA Paper | Open and Efficient Foundation Language Models | Autoencoding | Jun-2021 | The FAIR team of Meta AI |
| 153. | MarkupLM Paper | Pre-training of Text and Markup Language for Visually-rich Document Understanding | Autoencoding | Jun-2021 | Microsoft Research Asia |
| 154. | PoolFormer Paper | MetaFormer is Actually What You Need for Vision | Autoregressive | Jun-2021 | Sea AI Labs |
| 155. | QDQBert Paper | Principles and Empirical Evaluation | BERT-based | Jun-2021 | NVIDIA |
| 156. | ViLT Paper | Vision-and-Language Transformer Without Convolution or Region Supervision | Vision Transformer (ViT) | Jun-2021 | NAVER AI Lab/Kakao Enterprise/Kakao Brain |
| 157. | BARThez Paper | a Skilled Pretrained French Sequence-to-Sequence Model | Autoregressive | Jul-2021 | École polytechnique |
| 158. | Donut Paper | OCR-free Document Understanding Transformer | Time Series Transformer | Jul-2021 | NAVER |
| 159. | ImageGPT Paper | Generative Pretraining from Pixels | Autoregressive | Jul-2021 | OpenAI |
| 160. | OPT Paper | Open Pre-trained Transformer Language Models | Hybrid | Jul-2021 | Meta AI |
| 161. | Splinter Paper | Few-Shot Question Answering by Pretraining Span Selection | Hybrid | Jul-2021 | Tel Aviv University, |
| 162. | XGLM Paper | Few-shot Learning with Multilingual Language Models | Hybrid | Jul-2021 | Facebook AI |
| 163. | YOSO Paper | You Only Sample (Almost) | Object Detection | Jul-2021 | the University of Wisconsin - Madison |
| 164. | EfficientFormer Paper | Vision Transformers at MobileNetSpeed | Vision Transformer | Aug-2021 | Snap Research |
| 165. | ESM Paper | ESM-1b. Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences. ESM-1v was released with the paper Language models enable zero-shot prediction of the effects of mutations on protein function. ESM-2 and ESMFold were released with the paper Language models of protein sequences at the scale of evolution enable accurate structure prediction | Protein Transformer | Aug-2021 | Meta AI |
| 166. | Mask2Former Paper | Masked-attention Mask Transformer for Universal Image Segmentation | Autoencoding | Aug-2021 | FAIR and UIUC |
| 167. | MGP-STR Paper | Multi-Granularity Prediction for Scene Text Recognition | Autoencoding | Aug-2021 | Alibaba Research |
| 168. | NLLB Paper | Scaling Human-Centered Machine Translation | Autoencoding | Aug-2021 | Meta |
| 169. | T5v1.1 Paper | released in the repository google-research/text-to-text-transfer-transformer | Autoregressive | Aug-2021 | Google AI |
| 170. | TVLT Paper | Textless Vision-Language Transformer | Hybrid | Aug-2021 | UNC Chapel Hill |
| 171. | WavLM Paper | Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing | Autoregressive | Aug-2021 | Microsoft Research |
| 172. | XLM-RoBERTa-XL Paper | Larger-Scale Transformers for Multilingual Masked Language Modeling | BERT-based | Aug-2021 | Facebook AI, |
| 173. | Chinese-CLIP Paper | Contrastive Vision-Language Pretraining in Chinese | Vision-Language Pretraining | Sep-2021 | OFA-Sys |
| 174. | CLAP Paper | [Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation]https //arxiv.org/abs/2211.06687) | Vision Transformer | Sep-2021 | LAION-AI |
| 175. | Decision Transformer Paper | Reinforcement Learning via Sequence Modeling | Vision Transformer | Sep-2021 | Berkeley/Facebook/Google |
| 176. | BLIP-2 Paper | Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models | Vision Transformer | Oct-2021 | Salesforce |
| 177. | CANINE Paper | Pre-training an Efficient Tokenization-Free Encoder for Language Representation | Vision Transformer | Oct-2021 | Google Research |
| 178. | Graphormer Paper | Do Transformers Really Perform Bad for Graph Representation? | Autoencoding | Oct-2021 | Microsoft |
| 179. | I-BERT Paper | Integer-only BERT Quantization | Autoencoding | Oct-2021 | Berkeley |
| 180. | MatCha Paper | Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering | Autoencoding | Oct-2021 | Google AI |
| 181. | mLUKE Paper | The Power of Entity Representations in Multilingual Pretrained Language Models | Autoencoding | Oct-2021 | Studio Ousia |
| 182. | MobileViT Paper | Light-weight, General-purpose, and Mobile-friendly Vision Transformer | Autoencoding | Oct-2021 | Apple |
| 183. | OWL-ViT Paper | Simple Open-Vocabulary Object Detection with Vision Transformers | Vision Transformer (ViT) | Oct-2021 | Google AI |
| 184. | SpeechT5 Paper | Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing | Autoregressive | Oct-2021 | Microsoft Research |
| 185. | Swin Transformer V2 Paper | Scaling Up Capacity and Resolution | Vision Transformer (ViT) | Oct-2021 | Microsoft |
| 186. | ViTMAE Paper | Masked Autoencoders Are Scalable Vision Learners | Vision Transformer (ViT) | Oct-2021 | Meta AI |
| 187. | BLOOM Paper | The architecture of BLOOM is essentially similar to GPT3, but has been trained on 46 different languages and 13 programming languages. | Vision Transformer | Nov-2021 | BigScience workshop |
| 188. | ConvNeXTV2 Paper | Co-designing and Scaling ConvNets with Masked Autoencoders | Vision Transformer | Nov-2021 | Facebook AI |
| 189. | CPM-Ant Paper | Sequence-to-Sequence | Nov-2021 | OpenBMB | |
| 190. | GPT-Sw3 Paper | Building the First Large-Scale Generative Language Model for Swedish | Autoregressive | Nov-2021 | AI-Sweden |
| 191. | LongT5 Paper | Efficient Text-To-Text Transformer for Long Sequences | Autoregressive | Nov-2021 | Google AI |
| 192. | OneFormer Paper | One Transformer to Rule Universal Image Segmentation | Autoregressive | Nov-2021 | SHI Labs |
| 193. | Table Transformer Paper | Towards Comprehensive Table Extraction From Unstructured Documents | Hybrid | Nov-2021 | Microsoft Research |
| 194. | VAN Paper | Visual Attention Network | Vision Transformer (ViT) | Nov-2021 | Tsinghua University and Nankai University |
| 195. | AltCLIP Paper | Altering the Language Encoder in CLIP for Extended Language Capabilities | Vision-Language Pretraining | Dec-2021 | BAAI |
| 196. | MVP Paper | Multi-task Supervised Pre-training for Natural Language Generation | Autoencoding | Dec-2021 | RUC AI Box |
| 197. | NLLB-MOE Paper | Scaling Human-Centered Machine Translation | Autoencoding | Dec-2021 | Meta |
| 198. | PEGASUS-X Paper | Investigating Efficiently Extending Transformers for Long Input Summarization | Autoregressive | Dec-2021 | |
| 199. | Swin2SR Paper | SwinV2 Transformer for Compressed Image Super-Resolution and Restoration | Vision Transformer (ViT) | Dec-2021 | University of Würzburg |
| 200. | UL2 Paper | Unifying Language Learning Paradigms | Hybrid | Dec-2021 | Google Research |
| 201. | ViTMSN Paper | Masked Siamese Networks for Label-Efficient Learning | Vision Transformer (ViT) | Dec-2021 | Meta AI |
| 202. | YOLOS Paper | Rethinking Transformer in Vision through Object Detection | Object Detection | Dec-2021 | Huazhong University of Science & Technology |
| 203. | FLAN-T5 Paper | released in the repository google-research/t5x | Autoregressive | Feb-2022 | Google AI |
| 204. | GPT NeoX Japanese Paper | by Shinya Otani, Takayoshi Makabe, Anuj Arora, and Kyo Hattori. | Autoregressive | Feb-2022 | ABEJA |
| 205. | LayoutLMv3 Paper | Pre-training for Document AI with Unified Text and Image Masking | Autoencoding | Mar-2022 | Microsoft Research Asia |
| 206. | FLAN-UL2 Paper | released in the repository google-research/t5x | Autoregressive | Apr-2022 | Google AI |
| 207. | FLAVA Paper | A Foundational Language And Vision Alignment Model | Autoencoding | Apr-2022 | Facebook AI |
Authors of Above Papers#
| Sno. | Paper | Author |
|---|---|---|
| 1. | *AlexNet Paper | Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton |
| 2. | *VGG16 Paper | Karen Simonyan, Andrew Zisserman |
| 3. | *VGG19 Paper | Karen Simonyan, Andrew Zisserman |
| 4. | *ResNet Paper | by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. |
| 5. | *InceptionResNet Paper | Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Alex Alemi |
| 6. | *ConvNeXt Paper | Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, Kilian Weinberger |
| 7. | *DenseNet Paper | Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger |
| 8. | *MobileNetV1 Paper | by Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam. |
| 9. | *Xception Paper | François Chollet |
| 10. | EncoderDecoder Paper | by Sascha Rothe, Shashi Narayan, Aliaksei Severyn. |
| 11. | *MobileNetV2 Paper | by Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen. |
| 12. | Data2Vec Paper | by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli. |
| 13. | GPT Paper | by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever. |
| 14. | BERT Paper | by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova. |
| 15. | MarianMT Paper | by Jörg Tiedemann. The Marian Framework is being developed by the Microsoft Translator Team. |
| 16. | BiT Paper | by Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby. |
| 17. | Transformer-XL Paper | by Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov. |
| 18. | XLM Paper | by Guillaume Lample and Alexis Conneau. |
| 19. | CTRL Paper | by Nitish Shirish Keskar, Bryan McCann, Lav R. Varshney, Caiming Xiong and Richard Socher. |
| 20. | GPT-2 Paper | by Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodeiand Ilya Sutskever. |
| 21. | Funnel Transformer Paper | by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le. |
| 22. | *EfficientNet B0 Paper | Mingxing Tan, Quoc V. Le |
| 23. | ALBERT Paper | by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut. |
| 24. | EfficientNet Paper | by Mingxing Tan, Quoc V. Le. |
| 25. | MobileNetV3 Paper | Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, Hartwig Adam |
| 26. | Nezha Paper | by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu. |
| 27. | BART Paper | by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer. |
| 28. | ERNIE Paper | by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu. |
| 29. | ErnieM Paper | by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang. |
| 30. | FlauBERT Paper | by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab. |
| 31. | LXMERT Paper | by Hao Tan and Mohit Bansal. |
| 32. | Pegasus Paper | by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu. |
| 33. | XLNet Paper | by Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le. |
| 34. | BioGpt Paper | by Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu. |
| 35. | Hubert Paper | by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed. |
| 36. | REALM Paper | by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang. |
| 37. | SpeechToTextTransformer Paper | by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino. |
| 38. | XLM-V Paper | by Davis Liang, Hila Gonen, Yuning Mao, Rui Hou, Naman Goyal, Marjan Ghazvininejad, Luke Zettlemoyer, Madian Khabsa. |
| 39. | RoBERTa Paper | by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov. |
| 40. | GPT Neo Paper | by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy. |
| 41. | CamemBERT Paper | by Louis Martin, Benjamin Muller, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot. |
| 42. | DialoGPT Paper | by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan. |
| 43. | DistilBERT Paper | by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into DistilGPT2, RoBERTa into DistilRoBERTa, Multilingual BERT into DistilmBERT and a German version of DistilBERT. |
| 44. | LiLT Paper | by Jiapeng Wang, Lianwen Jin, Kai Ding. |
| 45. | LUKE Paper | by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto. |
| 46. | MobileBERT Paper | by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou. |
| 47. | MT5 Paper | by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel. |
| 48. | RAG Paper | by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela. |
| 49. | ConvBERT Paper | by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan. |
| 50. | Megatron-GPT2 Paper | by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro. |
| 51. | PhoBERT Paper | by Dat Quoc Nguyen and Anh Tuan Nguyen. |
| 52. | RoBERTa-PreLayerNorm Paper | by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli. |
| 53. | BERTweet Paper | by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen. |
| 54. | mBART Paper | by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer. |
| 55. | Megatron-BERT Paper | by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro. |
| 56. | SpeechToTextTransformer2 Paper | by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau. |
| 57. | BERT For Sequence Generation Paper | by Sascha Rothe, Shashi Narayan, Aliaksei Severyn. |
| 58. | ConvNeXT Paper | by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie. |
| 59. | ELECTRA Paper | by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning. |
| 60. | Longformer Paper | by Iz Beltagy, Matthew E. Peters, Arman Cohan. |
| 61. | RegNet Paper | by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár. |
| 62. | SqueezeBERT Paper | by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer. |
| 63. | LayoutLM Paper | by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou. |
| 64. | MPNet Paper | by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu. |
| 65. | VisualBERT Paper | by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang. |
| 66. | Conditional DETR Paper | by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang. |
| 67. | GPTBigCode Paper | by Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra. |
| 68. | M-CTC-T Paper | by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert. |
| 69. | Pix2Struct Paper | by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova. |
| 70. | ProphetNet Paper | by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou. |
| 71. | SEW Paper | by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi. |
| 72. | T5 Paper | by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu. |
| 73. | DeBERTa Paper | by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen. |
| 74. | Informer Paper | by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. |
| 75. | LED Paper | by Iz Beltagy, Matthew E. Peters, Arman Cohan. |
| 76. | SwitchTransformers Paper | by William Fedus, Barret Zoph, Noam Shazeer. |
| 77. | Whisper Paper | by Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever. |
| 78. | XLM-ProphetNet Paper | by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou. |
| 79. | XLM-RoBERTa Paper | by Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov. |
| 80. | Deformable DETR Paper | by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai. |
| 81. | FNet Paper | by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon. |
| 82. | GPTSAN-japanese Paper | by Toshiyuki Sakamoto(tanreinama). |
| 83. | SEW-D Paper | by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi. |
| 84. | CPM Paper | by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun. |
| 85. | GIT Paper | by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang. |
| 86. | LayoutXLM Paper | by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei. |
| 87. | DETR Paper | by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko. |
| 88. | GPT NeoX Paper | by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach |
| 89. | RemBERT Paper | by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder. |
| 90. | RoCBert Paper | by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou. |
| 91. | TAPAS Paper | by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos. |
| 92. | UPerNet Paper | by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun. |
| 93. | Vision Transformer (ViT) Paper | by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby. |
| 94. | Wav2Vec2 Paper | by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli. |
| 95. | PLBart Paper | by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang. |
| 96. | DiT Paper | by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei. |
| 97. | DPR Paper | by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. |
| 98. | GLPN Paper | by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim. |
| 99. | LeViT Paper | by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze. |
| 100. | NAT Paper | by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi. |
| 101. | TAPEX Paper | by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou. |
| 102. | VideoMAE Paper | by Zhan Tong, Yibing Song, Jue Wang, Limin Wang. |
| 103. | Wav2Vec2-Conformer Paper | by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino. |
| 104. | CLIP Paper | by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever. |
| 105. | XLS-R Paper | by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli. |
| 106. | Audio Spectrogram Transformer Paper | by Yuan Gong, Yu-An Chung, James Glass. |
| 107. | M2M100 Paper | by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin. |
| 108. | MEGA Paper | by Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May, and Luke Zettlemoyer. |
| 109. | BEiT Paper | by Hangbo Bao, Li Dong, Furu Wei. |
| 110. | BigBird-Pegasus Paper | by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed. |
| 111. | BigBird-RoBERTa Paper | by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed. |
| 112. | CLIPSeg Paper | by Timo Lüddecke and Alexander Ecker. |
| 113. | DPT Paper | by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun. |
| 114. | Perceiver IO Paper | by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira. |
| 115. | Reformer Paper | by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya. |
| 116. | RoFormer Paper | by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu. |
| 117. | Swin Transformer Paper | by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo. |
| 118. | TrOCR Paper | by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei. |
| 119. | Wav2Vec2Phoneme Paper | by Qiantong Xu, Alexei Baevski, Michael Auli. |
| 120. | X-CLIP Paper | by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling. |
| 121. | XLSR-Wav2Vec2 Paper | by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli. |
| 122. | Blenderbot Paper | by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston. |
| 123. | BlenderbotSmall Paper | by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston. |
| 124. | BLIP Paper | by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi. |
| 125. | ByT5 Paper | by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel. |
| 126. | CvT Paper | by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang. |
| 127. | DeBERTa-v2 Paper | by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen. |
| 128. | DeiT Paper | by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou. |
| 129. | GroupViT Paper | by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang. |
| 130. | LayoutLMv2 Paper | by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou. |
| 131. | MaskFormer Paper | by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov. |
| 132. | SegFormer Paper | by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo. |
| 133. | Time Series Transformer Paper | |
| 134. | TimeSformer Paper | by Gedas Bertasius, Heng Wang, Lorenzo Torresani. |
| 135. | Trajectory Transformer Paper | by Michael Janner, Qiyang Li, Sergey Levine |
| 136. | UniSpeech Paper | by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang. |
| 137. | UniSpeechSat Paper | by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu. |
| 138. | ALIGN Paper | by Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig. |
| 139. | BORT Paper | by Adrian de Wynter and Daniel J. Perry. |
| 140. | DePlot Paper | by Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun. |
| 141. | DETA Paper | by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl. |
| 142. | DiNAT Paper | by Ali Hassani and Humphrey Shi. |
| 143. | Jukebox Paper | by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever. |
| 144. | mBART-50 Paper | by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan. |
| 145. | Nyströmformer Paper | by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh. |
| 146. | ViT Hybrid Paper | by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby. |
| 147. | X-MOD Paper | by Jonas Pfeiffer, Naman Goyal, Xi Lin, Xian Li, James Cross, Sebastian Riedel, Mikel Artetxe. |
| 148. | BARTpho Paper | by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen. |
| 149. | BridgeTower Paper | by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan. |
| 150. | CodeGen Paper | by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong. |
| 151. | GPT-J Paper | by Ben Wang and Aran Komatsuzaki. |
| 152. | LLaMA Paper | by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. |
| 153. | MarkupLM Paper | by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei. |
| 154. | PoolFormer Paper | by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng. |
| 155. | QDQBert Paper | by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius. |
| 156. | ViLT Paper | by Wonjae Kim, Bokyung Son, Ildoo Kim. |
| 157. | BARThez Paper | by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis. |
| 158. | Donut Paper | by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park. |
| 159. | ImageGPT Paper | by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever. |
| 160. | OPT Paper | by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al. |
| 161. | Splinter Paper | by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy. |
| 162. | XGLM Paper | by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O’Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li. |
| 163. | YOSO Paper | |
| 164. | EfficientFormer Paper | by Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren. |
| 165. | ESM Paper | by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. |
| 166. | Mask2Former Paper | by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar. |
| 167. | MGP-STR Paper | by Peng Wang, Cheng Da, and Cong Yao. |
| 168. | NLLB Paper | by the NLLB team. |
| 169. | T5v1.1 Paper | by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu. |
| 170. | TVLT Paper | by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal. |
| 171. | WavLM Paper | by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei. |
| 172. | XLM-RoBERTa-XL Paper | by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau. |
| 173. | Chinese-CLIP Paper | by An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou. |
| 174. | CLAP Paper | |
| 175. | Decision Transformer Paper | by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch. |
| 176. | BLIP-2 Paper | by Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi. |
| 177. | CANINE Paper | by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting. |
| 178. | Graphormer Paper | by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu. |
| 179. | I-BERT Paper | by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer. |
| 180. | MatCha Paper | by Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos. |
| 181. | mLUKE Paper | by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka. |
| 182. | MobileViT Paper | by Sachin Mehta and Mohammad Rastegari. |
| 183. | OWL-ViT Paper | by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby. |
| 184. | SpeechT5 Paper | by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei. |
| 185. | Swin Transformer V2 Paper | by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo. |
| 186. | ViTMAE Paper | by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick. |
| 187. | BLOOM Paper | |
| 188. | ConvNeXTV2 Paper | by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie. |
| 189. | CPM-Ant Paper | |
| 190. | GPT-Sw3 Paper | by Ariel Ekgren, Amaru Cuba Gyllensten, Evangelia Gogoulou, Alice Heiman, Severine Verlinden, Joey Öhman, Fredrik Carlsson, Magnus Sahlgren. |
| 191. | LongT5 Paper | by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang. |
| 192. | OneFormer Paper | by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi. |
| 193. | Table Transformer Paper | by Brandon Smock, Rohith Pesala, Robin Abraham. |
| 194. | VAN Paper | by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu. |
| 195. | AltCLIP Paper | by Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell. |
| 196. | MVP Paper | by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen. |
| 197. | NLLB-MOE Paper | by the NLLB team. |
| 198. | PEGASUS-X Paper | by Jason Phang, Yao Zhao, and Peter J. Liu. |
| 199. | Swin2SR Paper | by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte. |
| 200. | UL2 Paper | by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler |
| 201. | ViTMSN Paper | by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas. |
| 202. | YOLOS Paper | by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu. |
| 203. | FLAN-T5 Paper | by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei |
| 204. | GPT NeoX Japanese Paper | |
| 205. | LayoutLMv3 Paper | by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei. |
| 206. | FLAN-UL2 Paper | by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei |
| 207. | FLAVA Paper | by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela. |
Conclusion#
I hope this article gave you an idea about Transformer architecture, their variants, their types, their birth chronology and the creators. As we have seen, the Transformer architecture has been a game-changer in natural language processing and computer vision tasks. It has been instrumental in enabling breakthroughs in machine translation, language understanding, and image classification, among other fields.
There are many types of Transformers, such as autoregressive models like GPT, autoencoding models like BERT and its variants, and hybrid models that combine the strengths of both. Additionally, there are many variants of the Transformer architecture, such as XLNet, RoBERTa, and T5, each with their unique contributions and improvements.
The Transformer’s birth chronology spans just a few years, from the original paper in 2017 to the latest models that are being developed today. Its creators include some of the most prominent names in the field of AI, such as Google, Facebook, and OpenAI.
As AI technology continues to evolve, we can expect more exciting developments in the field of Transformers, with even more powerful and sophisticated models that can tackle even more complex tasks. The Transformer architecture has shown us that there is still much to explore in the world of deep learning, and we can’t wait to see what the future holds.
Author
Dr Hari Thapliyaal
dasarpai.com
linkedin.com/in/harithapliyal
Comments: