Research: Sarcasm Detection System for Hinglish Language

Research: Sarcasm Detection System for Hinglish Language
Abstract
Hinglish is third most spoken language on the planet. Wikipage, states that 65% of Indian population is under 35 years age. Several disruptions like low cost mobile phone, extremely cheap data, digital India initiatives by government of India has caused huge surge in Hinglish language content. Hinglish language context is available in audio, video, images, and text format. We can find Hinglish content in comment box of product, new articles, service feedback, WhatsApp, social media like YouTube, Facebook, twitter etc. To engage with consumer, it is extremely important to analyse the sentiments, but to perform sentiment analysis it is not possible to read every comment or feedback using human eyes. With the increasing number of education and sophisticated people in Indian society it is evident that people do not say negative things directly even when they want to say. Generally, an educated and advance mind is more diplomatic than less educated or village people who are not exposed enough to the world. Due to this reason people use more sarcastic language, they say negative things in positive words. Thus, it becomes necessary to identify the true sentiments in the text available on social media or product review or comment pages. In this paper we are demonstrating a system which can help in automatic sarcasm detection in Hinglish language. This work is also extracting text from Hindi twitter handles and Hindi blogs and creating a dataset. The dataset contains the tweets which are written in Roman or Devanagari scripts, words can be from any Indian language or English. In this research no word, either Indian language words written in Roman or English word written in Devanagari is translated or transliterated. A series of data cleaning activities are performed on the text extracted from blogs and twitter. We developed our dataset with the help of 3 Hinglish language speakers. Ten embeddings were built in this work. Four embeddings were finetuned using Transfer embedding, another four embedding were built using training data and standard NLP libraries, one from lexical features and one from lexical features + best embedding. In this work we used ten classification libraries for classification work. In total we developed 109 classification models and analysed the performance of those models against the embedding and classifier used. Four classification models were developed using neural network. Our best model with fastTextWiki embedding and Naïve Bayesian classifier gives 76% accuracy, 78% recall, 75% precision, 76% F1 score and 80% AUC.
Technology Used
- Transfromers & Frameworks: mBERT, FastText, IndicFT, IndicBERT, CNN, RNN, Kaggle, Colab
- Machine Learning Libraries: NLTK, RE, Pandas, Scikit-Learn, Seaborn, Wordcloud, Markdown, Python, Selinium, numpy,
- ML Algorithms: Naive Bayesian, SVM, XG Boost, Logistic Regression, AdaBoost, Gradient Boost Classifier, Random Forest Classifier, Light Gradient Boost, Peceptron, Decision Tree
- Embedding: TFIDF, Word2Vec, BoW, GloVe, Lexical, FastText/Wiki, IndicFT, IndicBERT,
- Eval Metrics: Accuracy, Recall, Precision, F1 Score
Evolution of Hinglish

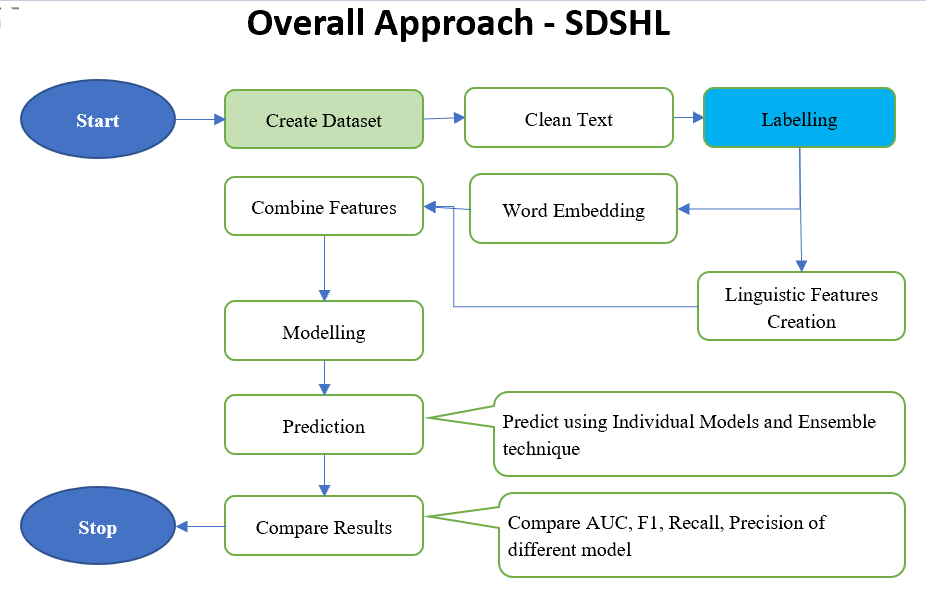
Overall Approach
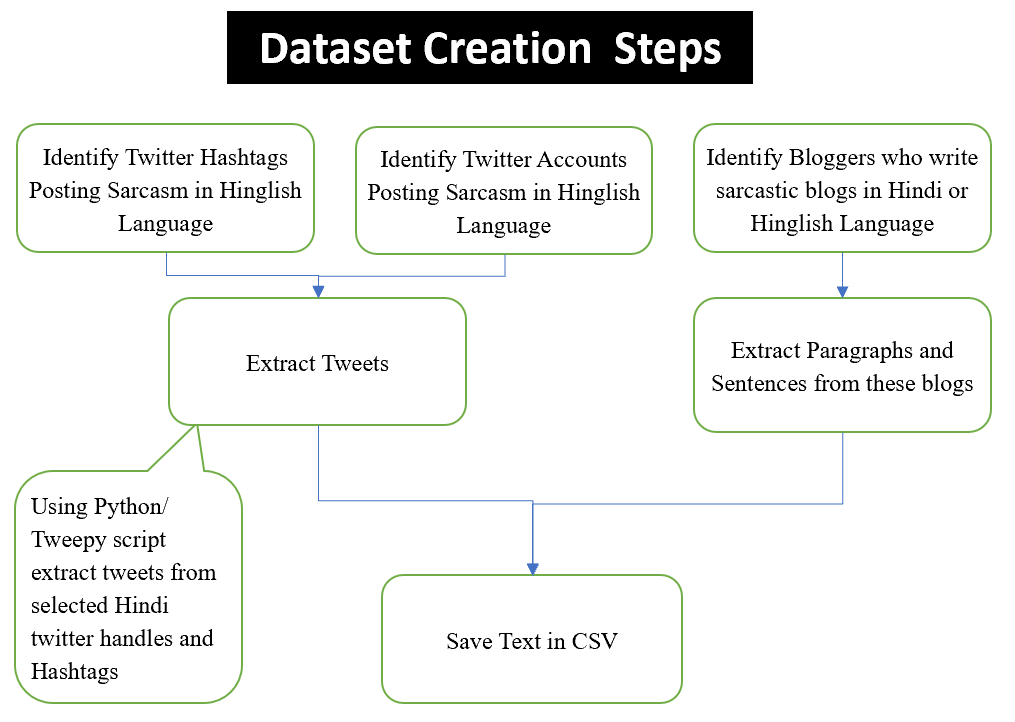
Dataset Creation Steps
Text Cleaning Steps

Classifier and Embeddings

Contribution of Work
- We created sarcasm dataset in Hinglish languages of 2000 sentences, and it can be used by other researchers to create their models or expend this dataset.
- We identified good embedding (fastTextWiki and IndicFT) for finetuning, these are more effective for Hinglish language sarcasm detection work.
- We established if combine embedding with classical ML classifier we get good results, provided we have good embedding.
- We identified, if we do task transfer then which models can be used for getting good results on Hinglish Language sarcasm detection work.
Future Recommendations
-
Dataset : Our dataset has only 2000 sentences. To make a stable model we need more data for this sarcasm classification task. Hence, in future work we should focus on expending the dataset. We should include more Hinglish language text. Create a balance dataset from twitter and blog text.
-
Classifiers & Task Transfer : We have tried task transfer and we also used classical ML classifier with embedding transfer, embedding creation and lexical feature. We got good results even with task transfer. We would recommend using more sophisticated models like GPT3 in future experiments and conduct those experiments on GPU/ TPU machines with more data. As NB \& SVM is giving good results so we would recommend to use these classifiers with embedding transfer.
-
Embedding : We used mBERT, fastTextWiki, IndicFT and IndicBERT to finetune and transfer embedding. These models are primarily trained on the corpus of Devanagari script and Hindi language. In the real world around text us is not purely in Devanagari script and Hindi language. Therefore, we cannot rely on the embedding of these models for good results. Hence, we need to collect a huge size corpus from social media communication of Hinglish language and create an embedding model.
-
Language Treatment of words in the Sentence : We know Roman typing is much easy compare to typing in Devanagari therefore many time people use Roman letters in between the sentence. This is true especially if it is name of politician, film actor, place name, movie name, event name (#AmitShah, #Modi, #Khan, #India #Bollywood, #Delhi, #Karnataka #Yogi, #Dangal #Deepoutsav) etc. If we are using transfer learning for a model created using non-Hinglish corpus then we need to transliterate all these words into Devanagari script. We attempted this work in our project, but we could not do this successfully and in future we need to find or develop a library which can do this transliteration in a most reliable way. We think this transliteration can be summarised as below.
- Hindi word in Devanagari: No change required.
- Non-Hindi Indian words in Devanagari: Words from other language like Urdu, Punjabi, Marathi like खत्म, खल्लास, गजल, सोन्देश, मसवरा दास्तां खबर should be left as is.
- English words in Devanagari: English words written in Devanagari like “राइस” “विन” “ग्रेट” should be left as is.
- Hindi/Non-English word in Roman script words: Hindi/Non-English words written in roman scripts like “Aap to Mahan hai”, “tussi great ho ji” should be transliterated to Devanagari. So, it will be like “आप तो महान हैं”
- English words in Roman: English words in Roman like “friend”, “love” in between Hinglish sentence e.g. “मैं अपने friend को love करता हूं”, we should transliterate “friend” to Devanagari and we should not try to translate this. So, new sentence should be “. “मैं अपने फ्रेंड को लव करता हूं” and not like this “मैं अपने मित्र को प्यार करता हूं”
Research Report
Details report is available on the request.