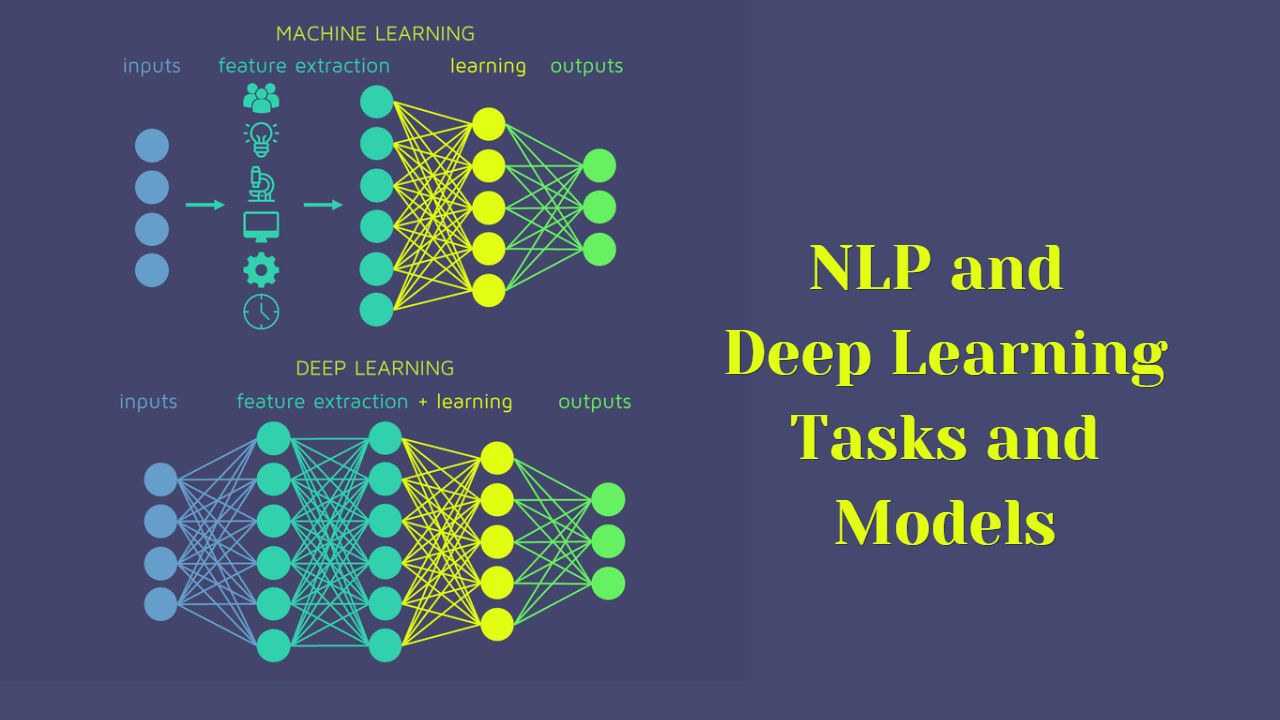
Machine Learning Tasks and Model Evaluation less than 1 minute read Machine Learning Tasks and Model EvaluationPermalink I am sorry, this page has moved to different location. Click me to go there Share on Twitter Facebook LinkedIn Previous Next