State of the Art Computer Vision Models: A Comprehensive Overview

State of the Art Computer Vision ModelsPermalink
What are the different methods of Image generation?Permalink
There are several methods for image generation. Diffusion models are currently the state-of-the-art due to their balance of quality, flexibility, and scalability. However, other methods like GANs and autoregressive models remain relevant for specific use cases. Let’s see them one by one.
1. Diffusion ModelsPermalink
Diffusion models are a class of generative models that work by gradually adding noise to data (e.g., images) and then learning to reverse this process to generate new data. Here’s how it works:
Key Steps in Diffusion Models:Permalink
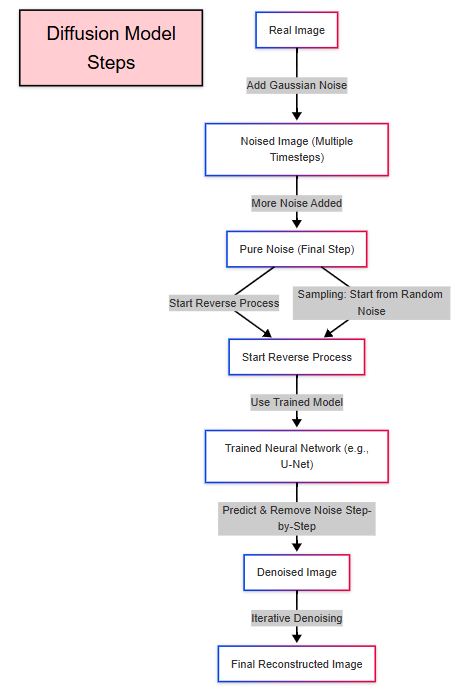
Variants of Diffusion Models:Permalink
- Denoising Diffusion Probabilistic Models (DDPM): The original formulation of diffusion models.
- Latent Diffusion Models (LDM): Operate in a lower-dimensional latent space for efficiency (e.g., Stable Diffusion).
- Classifier-Free Guidance: Improves image quality by balancing conditional and unconditional generation.
- Stochastic Differential Equations (SDEs): A continuous-time formulation of diffusion models.
Advantages:Permalink
- High-quality, photorealistic images.
- Flexible and controllable generation (e.g., text-to-image, image-to-image).
- Scalable to high resolutions.
Examples Models:Permalink
- DALL·E 3, Stable Diffusion, Imagen, Midjourney.
2. Generative Adversarial Networks (GANs)Permalink
GANs consist of two neural networks: a generator and a discriminator, which compete against each other.
Key Steps in GANs:Permalink
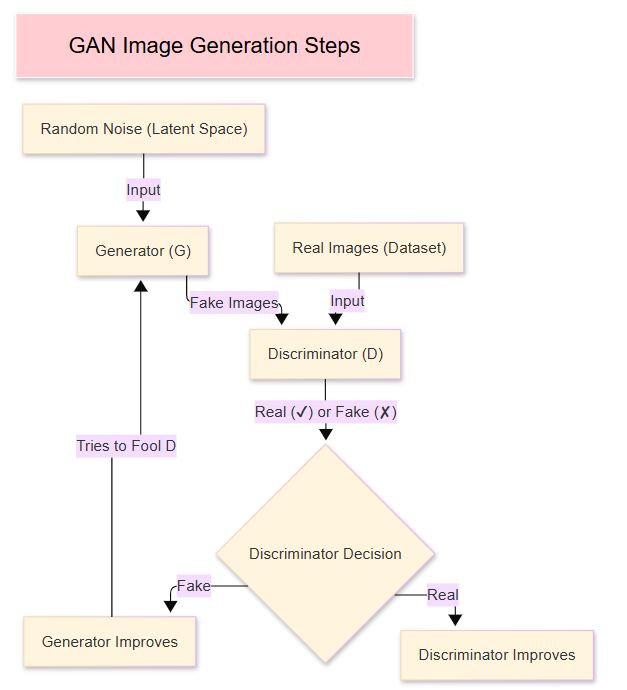
Advantages:Permalink
- Fast image generation once trained.
- High-quality results for specific tasks (e.g., faces, landscapes).
Challenges:Permalink
- Training instability (mode collapse).
- Limited diversity in generated images.
Examples:Permalink
- StyleGAN, BigGAN, CycleGAN.
3. Variational Autoencoders (VAEs)Permalink
VAEs are probabilistic models that learn a latent representation of data.
Key Steps in VAEs:Permalink
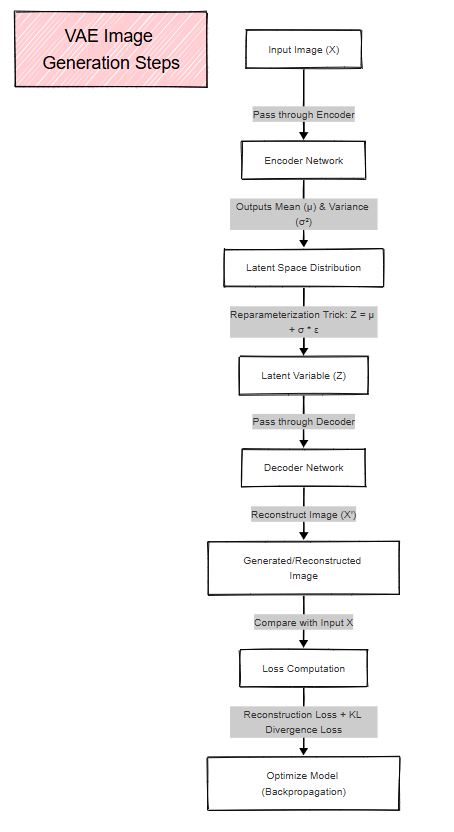
Advantages:Permalink
- Smooth latent space for interpolation.
- Good for tasks requiring structured outputs.
Challenges:Permalink
- Generated images are often blurrier compared to GANs or diffusion models.
Examples:Permalink
- VQ-VAE, NVAE.
4. Autoregressive ModelsPermalink
Autoregressive models generate images pixel by pixel or patch by patch, conditioned on previously generated pixels.
Key Steps in Autoregressive Models:Permalink
- Treat image generation as a sequence prediction problem.
- Use models like Transformers or RNNs to predict the next pixel or patch.
Advantages:Permalink
- High-quality, detailed images.
- Flexible and scalable.
Challenges:Permalink
- Slow generation due to sequential nature.
- Computationally expensive.
Examples:Permalink
- PixelRNN, PixelCNN, Image GPT.
5. Flow-Based ModelsPermalink
Flow-based models use invertible transformations to map data to a latent space and back.
Key Steps in Flow-Based Models:Permalink
- Learn a bijective (invertible) mapping between the data distribution and a simple latent distribution (e.g., Gaussian).
- Generate new images by sampling from the latent distribution and applying the inverse transformation.
Advantages:Permalink
- Exact likelihood estimation.
- Efficient sampling.
Challenges:Permalink
- Limited flexibility in architecture due to invertibility constraints.
Examples:Permalink
- Glow, RealNVP.
6. Neural Radiance Fields (NeRF)Permalink
NeRF is a method for 3D scene reconstruction and generation.
Key Steps in NeRF (Neural Radiance Fields)Permalink
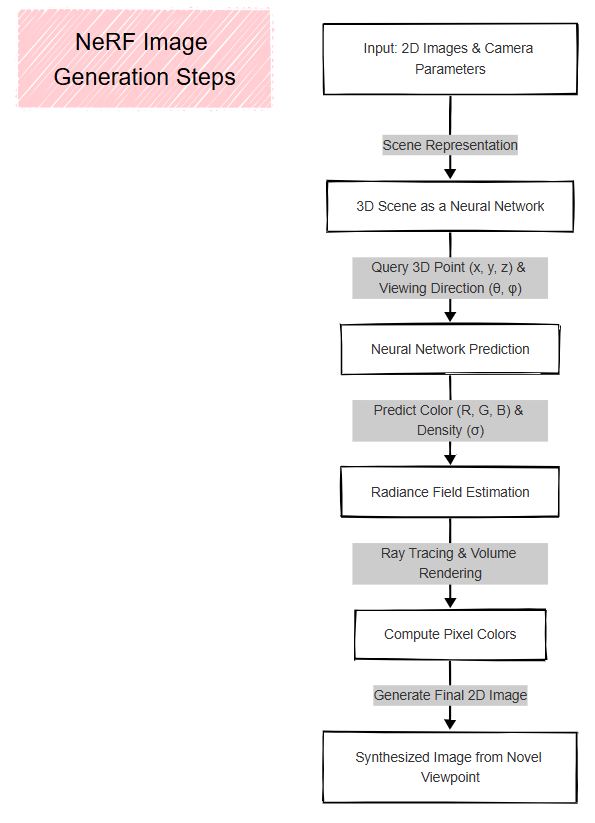
Scene Representation (Implicit 3D Model)Permalink
- The 3D scene is represented as a continuous volumetric function.
- Instead of using meshes or point clouds, NeRF models a scene as a neural network mapping 3D coordinates to color and density.
- Input:
- A set of 2D images of a scene taken from different angles.
- The camera parameters (position & direction) for each image.
Neural Network Prediction (Radiance Field Estimation)Permalink
- A deep neural network takes in a 3D point (x, y, z) and a viewing direction (θ, φ).
- It predicts:
- Color (R, G, B) → Light emitted from that point.
- Density (σ) → How much light is absorbed at that point.
- This allows NeRF to model the appearance of a scene from any viewpoint.
Volume Rendering (Synthesizing 2D Images)Permalink
- To generate an image, NeRF traces rays through the scene from the camera viewpoint.
- For each ray:
- Samples multiple points along the ray in 3D space.
- Uses the neural network to get color and density at each sampled point.
- Combines these values using volume rendering equations to compute the final pixel color.
- This step synthesizes realistic 2D images from new viewpoints.
Advantages:Permalink
- High-quality 3D-aware image generation.
- Useful for tasks like view synthesis.
Challenges:Permalink
- Computationally intensive.
- Limited to 3D scenes.
Examples:Permalink
- GIRAFFE, DreamFusion.
7. Transformer-Based ModelsPermalink
Transformers, originally designed for NLP, are now used for image generation.
Key Steps in Transformer-Based Models:Permalink
- Treat images as sequences of patches or tokens.
- Use self-attention mechanisms to model relationships between patches.
- Generate images autoregressively or in parallel.
Advantages:Permalink
- Scalable to large datasets.
- High-quality results with sufficient compute.
Challenges:Permalink
- High computational cost.
- Requires large datasets.
Examples:Permalink
- DALL·E, Image GPT, Pathways Autoregressive Text-to-Image mode (Parti).
Summary of Methods:Permalink
| Method | Key Idea | Strengths | Weaknesses |
|---|---|---|---|
| Diffusion Models | Gradually denoise random noise into images. | High quality, flexible, scalable. | Computationally expensive. |
| GANs | Adversarial training between generator and discriminator. | Fast generation, high quality. | Training instability, limited diversity. |
| VAEs | Learn latent representations and decode them into images. | Smooth latent space, structured outputs. | Blurry images. |
| Autoregressive | Generate images pixel-by-pixel or patch-by-patch. | High detail, flexible. | Slow generation, expensive. |
| Flow-Based | Use invertible transformations to map data to latent space. | Exact likelihood, efficient sampling. | Limited flexibility. |
| NeRF | Represent 3D scenes as volumetric functions. | High-quality 3D-aware generation. | Computationally intensive. |
| Transformers | Treat images as sequences of patches and use self-attention. | Scalable, high quality. | High compute and data requirements. |
What are the state-of-the-art models for image generation?Permalink
1. FLUX.1 and Ideogram2.0Permalink
- Method: Diffusion models with advanced prompt-following capabilities.
- Description: These models excel in structured output generation, realism, and physical consistency. They are capable of generating high-quality images from text prompts and are considered leading models in the field.
2. DALL·E 3 HDPermalink
- Method: Diffusion models with enhanced text rendering and coherence.
- Description: DALL·E 3 is known for its ability to generate detailed and coherent images from complex text descriptions. It incorporates a provenance classifier to identify AI-generated images.
3. Stable Diffusion XL Base 1.0 (SDXL)Permalink
- Method: Latent Diffusion Models (LDM) with ensemble pipelines.
- Description: SDXL generates high-resolution, diverse images with superior fidelity. It uses two pre-trained text encoders and a refinement model for enhanced detail and denoising.
4. Imagen 3Permalink
- Method: Diffusion models with SynthID watermarking.
- Description: Imagen 3 produces photorealistic images with rich details and lighting. It includes a digital watermarking tool (SynthID) embedded directly into the image pixels.
5. Midjourney v6.1Permalink
- Method: Diffusion models with creative remix capabilities.
- Description: Midjourney is renowned for its artistic style and ability to generate highly aesthetic, photorealistic images. It supports higher resolutions and offers upscaling options.
6. FreCaS (Frequency-aware Cascaded Sampling)Permalink
- Method: Frequency-aware cascaded sampling for higher-resolution image generation.
- Description: FreCaS decomposes the sampling process into stages with gradually increased resolutions, optimizing computational efficiency and image quality. It is particularly effective for generating 2048x2048 images.
7. ControlARPermalink
- Method: Autoregressive models with spatial control.
- Description: ControlAR supports arbitrary-resolution image generation with spatial controls like depth maps, edge detection, and segmentation masks. It integrates DINOv2 encoders for enhanced control.
8. QLIP (Quantized Language-Image Pretraining)Permalink
- Method: Binary-spherical-quantization-based autoencoder.
- Description: QLIP unifies multimodal understanding and generation by combining reconstruction and language-image alignment objectives. It serves as a drop-in replacement for visual encoders in models like LLaVA and LlamaGen.
9. Recraft V3Permalink
- Method: Diffusion models with precise control over image attributes.
- Description: Recraft V3 excels in generating images with extended text content and offers granular control over text size, positioning, and style. It is designed for professional designers.
10. Luma Photon FlashPermalink
- Method: Diffusion models optimized for efficiency and quality.
- Description: Luma Photon Flash is up to 10 times more efficient than other models, delivering high-quality and creative outputs. It supports multi-turn and iterative workflows.
11. Playground v3 (Beta)Permalink
- Method: Diffusion models with deep prompt understanding.
- Description: Playground v3 focuses on precise control over image generation, excelling in detailed prompts and text rendering. It integrates LLM and advanced VLM captioning for enhanced performance.
12. DeepSeek JanusPermalink
- Method: Open-source diffusion models with multimodal understanding.
- Description: DeepSeek Janus is a research-oriented model that generates detailed, structured imagery. It is popular among developers for its flexibility and customization options.
13. OmniGenPermalink
- Method: Multimodal generative models.
- Description: OmniGen integrates text, image, and audio data into a unified generative framework, eliminating the need for additional preprocessing steps like face detection or pose estimation.
14. Gen2 by RunwayPermalink
- Method: Text-to-video generation with multimodal input.
- Description: While primarily a video generation tool, Gen2 can create high-quality images from text prompts and supports extensive customization, including reference images and audio.
15. Dreamlike-photoreal-2.0Permalink
- Method: Fine-tuned diffusion models.
- Description: Specializing in photorealistic image generation, this model is derived from Stable Diffusion and is fine-tuned using user-contributed data.
Summary Table of SOTA Image generation modelsPermalink
Certainly! Here’s the updated table with the first column now containing the URLs of the official pages or research papers for each model:
State-of-the-Art Image Generation ModelsPermalink
| Model | Developer | Key Features | Open-Source |
|---|---|---|---|
| FLUX.1 | Black Forest Labs | Advanced text-to-image generation with high fidelity and photorealism. | Yes |
| Ideogram 2.0 | Ideogram | Text-integrated image generation, excelling in rendering legible text within images. | Yes |
| DALL·E 3 HD | OpenAI | High-definition image generation from textual descriptions. | No |
| Stable Diffusion XL Base 1.0 (SDXL) | Stability AI | High-resolution image synthesis with improved detail and coherence. | Yes |
| Imagen 3 | Google Research | Diffusion-based model for generating high-quality images from text prompts. | No |
| Midjourney v6.1 | Midjourney | AI-driven image generation with a focus on artistic styles and creativity. | No |
| FreCaS (Frequency-aware Cascaded Sampling) | Various researchers | Advanced sampling technique for improved image quality in generative models. | Yes |
| ControlAR | Various researchers | Augmented reality integration with image generation capabilities. | Yes |
| QLIP (Quantized Language-Image Pretraining) | Various researchers | Pretraining method for enhancing language-image understanding in models. | Yes |
| Recraft V3 | Recraft AI | AI image generator focusing on realistic and detailed image creation. | Yes |
| Luma Photon Flash | Luma AI | AI-powered tool for generating high-quality images with flash photography effects. | Yes |
| Playground v3 (Beta) | Playground AI | Interactive platform for experimenting with various AI image generation models. | Yes |
| DeepSeek Janus | DeepSeek AI | Dual-purpose AI model for both image generation and analysis. | Yes |
| OmniGen | Omni AI | Versatile image generation model capable of producing a wide range of styles. | Yes |
| Gen2 by Runway | Runway | Advanced text-to-image model with high-resolution output and creative flexibility. | No |
| Dreamlike-photoreal-2.0 | Dreamlike AI | AI model specializing in photorealistic image generation from textual prompts. | Yes |
What are the state-of-the-art Video generation models?Permalink
1. Gen-2 by RunwayPermalink
- Developer: Runway
- Description: A state-of-the-art text-to-video generation model that can create high-quality videos from text prompts, images, or other videos. It supports multimodal inputs and offers extensive customization options.
- Key Features:
- Text-to-video, image-to-video, and video-to-video generation.
- High-resolution outputs with realistic motion and details.
2. Sora by OpenAIPermalink
- Developer: OpenAI
- Description: A groundbreaking text-to-video model capable of generating high-fidelity, photorealistic videos from text descriptions. Sora is designed to understand and simulate complex real-world dynamics.
- Key Features:
- Long-duration video generation (up to several minutes).
- High-quality visuals with realistic physics and interactions.
3. Phenaki by Google ResearchPermalink
- Developer: Google Research
- Description: A text-to-video model that generates videos from textual descriptions. Phenaki is known for its ability to produce coherent and temporally consistent videos.
- Key Features:
- Long-form video generation.
- High temporal consistency and visual quality.
4. Imagen Video by Google ResearchPermalink
- Developer: Google Research
- Description: A diffusion-based text-to-video model that builds on the success of Imagen (an image generation model). It generates high-resolution videos with rich details and smooth motion.
- Key Features:
- High-resolution video generation (e.g., 1280x768).
- Fine-grained control over video content.
5. Make-A-Video by Meta (Facebook AI)Permalink
- Developer: Meta (Facebook AI)
- Description: A text-to-video generation model that leverages advancements in image generation and applies them to video. It generates videos from text prompts with realistic motion and details.
- Key Features:
- High-quality video generation with smooth transitions.
- Supports creative and diverse video outputs.
6. CogVideo by Tsinghua University and ModelBestPermalink
- Developer: Tsinghua University and ModelBest
- Description: A text-to-video generation model based on the CogView framework. It uses a transformer-based architecture to generate videos from text descriptions.
- Key Features:
- High-quality video generation with fine-grained details.
- Supports long-duration videos.
7. Video LDM (Latent Diffusion Model)Permalink
- Developer: Researchers from various institutions (e.g., LMU Munich, Heidelberg University)
- Description: A video generation model based on latent diffusion models (LDMs). It extends the success of LDMs in image generation to the video domain.
- Key Features:
- High-resolution video generation.
- Efficient training and inference.
8. NUWA by Microsoft Research AsiaPermalink
- Developer: Microsoft Research Asia
- Description: A multimodal generative model that can generate videos from text, images, or sketches. NUWA is designed for a wide range of creative tasks.
- Key Features:
- Text-to-video, image-to-video, and sketch-to-video generation.
- High-quality outputs with diverse styles.
9. T2V-Zero (Text-to-Video Zero-Shot)Permalink
- Developer: Researchers from various institutions
- Description: A zero-shot text-to-video generation model that can create videos from text prompts without requiring task-specific training.
- Key Features:
- Zero-shot video generation.
- High flexibility and adaptability.
10. VideoGPT by OpenAIPermalink
- Developer: OpenAI
- Description: A video generation model based on the GPT architecture. It generates videos by predicting the next frame in a sequence, similar to how GPT models predict the next word in a sentence.
- Key Features:
- High-quality video generation.
- Scalable and flexible architecture.
11. DIGAN (Diverse Image and Video Generation via Adversarial Networks)Permalink
- Developer: Researchers from various institutions
- Description: A generative adversarial network (GAN) designed for diverse image and video generation. DIGAN focuses on generating high-quality and diverse video outputs.
- Key Features:
- High diversity in generated videos.
- Realistic and detailed outputs.
12. Video Diffusion ModelsPermalink
- Developer: Researchers from various institutions
- Description: A class of video generation models based on diffusion models. These models extend the success of diffusion models in image generation to the video domain.
- Key Features:
- High-quality video generation.
- Fine-grained control over video content.
13. Text2Video-ZeroPermalink
- Developer: Researchers from various institutions
- Description: A zero-shot text-to-video generation model that leverages pretrained image generation models (e.g., Stable Diffusion) to generate videos without additional training.
- Key Features:
- Zero-shot video generation.
- High flexibility and efficiency.
14. VideoPoet by Google ResearchPermalink
- Developer: Google Research
- Description: A video generation model that focuses on creating high-quality, creative videos from text prompts. It uses a transformer-based architecture for video synthesis.
- Key Features:
- High-quality and creative video outputs.
- Supports diverse video styles.
15. MagicVideo by ByteDancePermalink
- Developer: ByteDance
- Description: A text-to-video generation model developed by ByteDance. It generates high-quality videos from text prompts with realistic motion and details.
- Key Features:
- High-resolution video generation.
- Efficient and scalable architecture.
Summary of SOTA Video Generation ModelsPermalink
| Model | Developer | Key Features | Open-Source |
|---|---|---|---|
| Gen-2 (🔗) | Runway | Text-to-video, image-to-video, high-resolution outputs. | No |
| Sora (🔗) | OpenAI | Long-duration, photorealistic videos with realistic physics. | No |
| Phenaki (📄) | Google Research | Long-form, temporally consistent videos. | No |
| Imagen Video (🔗) | Google Research | High-resolution, diffusion-based video generation. | No |
| Make-A-Video (🔗) | Meta (Facebook AI) | High-quality, smooth transitions. | No |
| CogVideo (📄) | Tsinghua University, ModelBest | Transformer-based, long-duration videos. | Yes |
| Video LDM (📄) | LMU Munich, Heidelberg Univ. | Latent diffusion models for high-resolution videos. | Yes |
| NUWA (📄) | Microsoft Research Asia | Multimodal (text, image, sketch) video generation. | No |
| T2V-Zero (📄) | Various researchers | Zero-shot text-to-video generation. | Yes |
| VideoGPT (📄) | OpenAI | GPT-based video generation. | Yes |
| DIGAN (📄) | Various researchers | GAN-based diverse video generation. | Yes |
| Video Diffusion (📄) | Various researchers | Diffusion-based high-quality video generation. | Yes |
| Text2Video-Zero (📄) | Various researchers | Zero-shot video generation using pretrained models. | Yes |
| VideoPoet (📄) | Google Research | Transformer-based creative video synthesis. | No |
| MagicVideo (📄) | ByteDance | High-resolution, efficient text-to-video generation. | No |
Notes:
- 🔗 = Official website/demo
- 📄 = Research paper link
- Open-source models generally have GitHub repositories available.
What are State-of-the-Art (SOTA) 3D Image Generation Models?Permalink
| Model | Developer | Key Features | Open-Source |
|---|---|---|---|
| Direct3D | Nanjing University | Scalable 3D generation from images using a 3D Latent Diffusion Transformer. | Yes |
| GIRAFFE HD | UC San Diego | High-resolution 3D-aware generative model for controllable image generation. | Yes |
| InstantMesh | Tsinghua University | Efficient 3D mesh generation from a single image using sparse-view reconstruction. | Yes |
| Zero-1-to-3 | Columbia University | Zero-shot 3D object generation from a single RGB image. | Yes |
| Meta 3D Gen | Meta AI | Fast pipeline for text-to-3D asset generation. | No |
| Unique3D | Tsinghua University | High-fidelity textured mesh generation from a single orthogonal RGB image. | Yes |
| Cube 2.0 | Common Sense Machines | AI foundation model for image-to-3D conversion in seconds. | No |
Categories:
About the Author

Dr. Hari Thapliyal is a prolific blogger and seasoned professional with an extensive background in Data Science, Project Management, and Advait-Vedanta Philosophy. He holds a Doctorate in AI/NLP from SSBM, Geneva, along with Master’s degrees in Computers, Business Management, Data Science, and Economics. With over three decades of experience in management and leadership, Hari has extensive expertise in training, consulting, and coaching within the technology sector. His specializations include Data Science, AI, Computer Vision, NLP, and machine learning. Hari is also passionate about meditation and nature, often retreating to secluded places for reflection and peace.